This is the first post of a series on full stack ML application with PyTorch, where I logged my learnings on reimplementing the Full Stack Deep Learning project (2018 March) (link) in PyTorch (originally in Keras). To get the most out of this series, it’s preferred that you’ve gone through the lecture series and the repo, know basics of deep learning frameworks Keras and PyTorch, and know basic Neural Nets (CNN, LSTM etc).
This post summarizes my general learning from the project. In the following posts I will specifically talk about my (re)implementation experience in three aspects: Neural Net (NN-wise), Dataset API (Data-wise), and coordination (Ops-wise). I will also mention my major roadblocks along the way, and small traps that are worth noting. Here is the structure of this series:
- Overview: goal, eng design, performance, general learnings
- Lab2: single char prediction: get familiar with the project setup (link)
- Lab3-5: line recognition with CTC loss (link)
- Lab6: line detection (link)
- Lab7-9: MLOps: data versioning, CI, model serving (link)
Goal
The goal of this project is to implement an end-to-end DL-based OCR system: it takes an image with multiple lines of handwriting, and outputs multiple sequences of characters.
From ML side, this system contains an image detection model (takes an image of multiple lines, outputs the location of lines) and an image classification model (takes an image of line, outputs a sequence of characters).
From engineering side, this system implements modules for experiment logging, data versioning, CI and testing, and model serving. The original repo can already run properly with Keras and a certain stack, my posts are focusing on how to re-implement it with PyTorch (plus some other stack).
Engineering Design
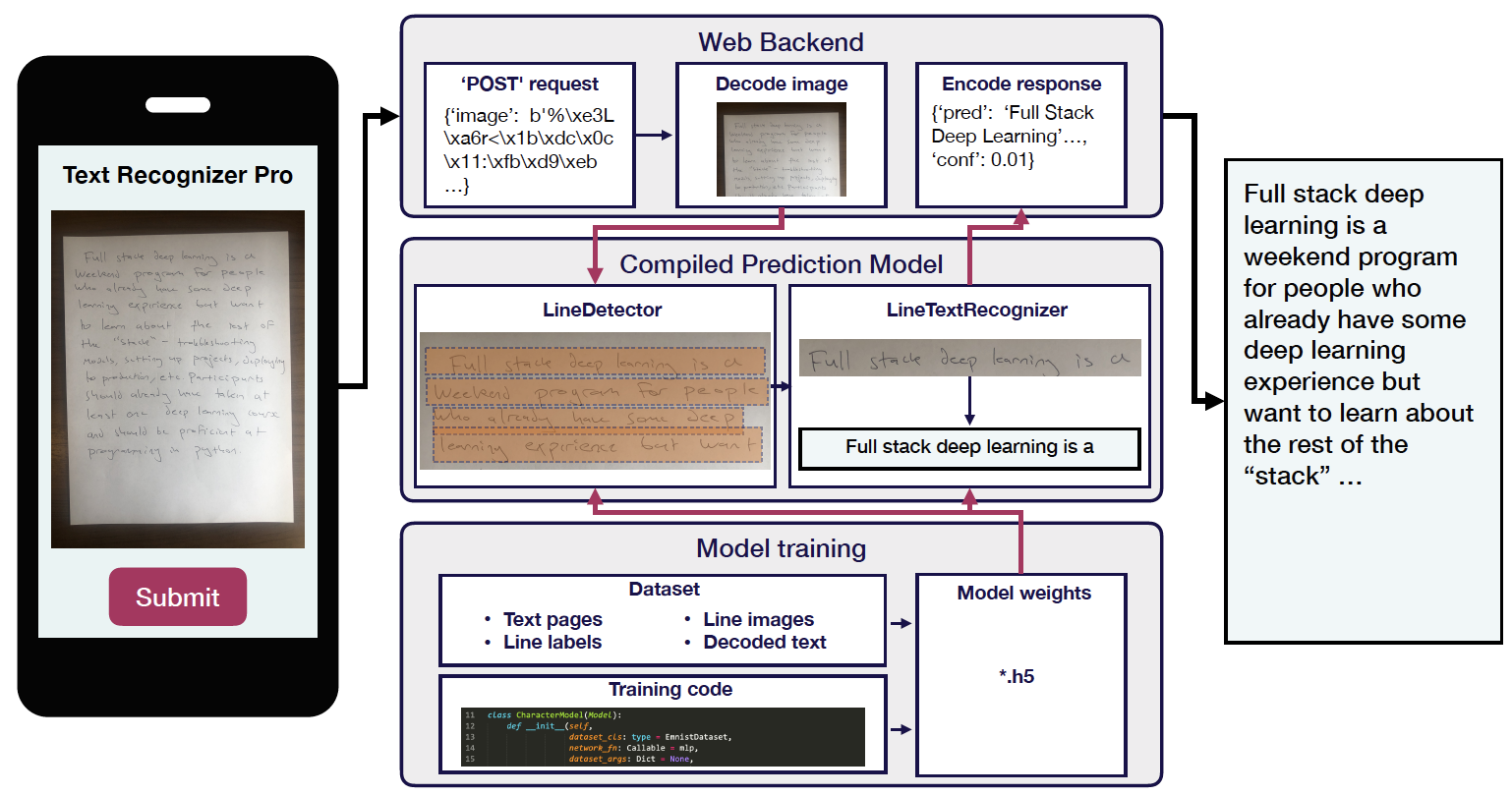
Details see the below image (taken from the original repo). There are 4 main design decisions:
ML pipeline
It's a tandem of line detection model - line classification model, rather than one end-to-end model.
Model
The Model class contains Dataset + Network + Config1 + methods e.g. fit/eval/loss, as well as util functions to process image.
Two layers of Config
The highest level of Config is a json file specifing the type of Model, Dataset, Network and their hyperparameters, as well as the training process. The subset of Config that contains Dataset and Network info becomes the Config1 above and fed to Model. The class loading with string is enabled by leveraging such patterns:
networks_module = importlib.import_module("text_recognizer.networks")
network_fn_ = getattr(networks_module, experiment_config["network"])
run_experiment
A function that takes the highest level Config and prepare model objects and training process. This is only for parsing and orchestration, no 'real' work.
Performance
Accuracy
Line detection:
| network | Pixel Acc |
|---|---|
| FCN | 0.928 |
| UNet | 0.954 |
Line Prediction:
| network | Character Acc |
|---|---|
| sliding + cnn + rnn + CTC loss | 0.765 |
| crnn + CTC loss | 0.808 |
| seq2seq | TBD |
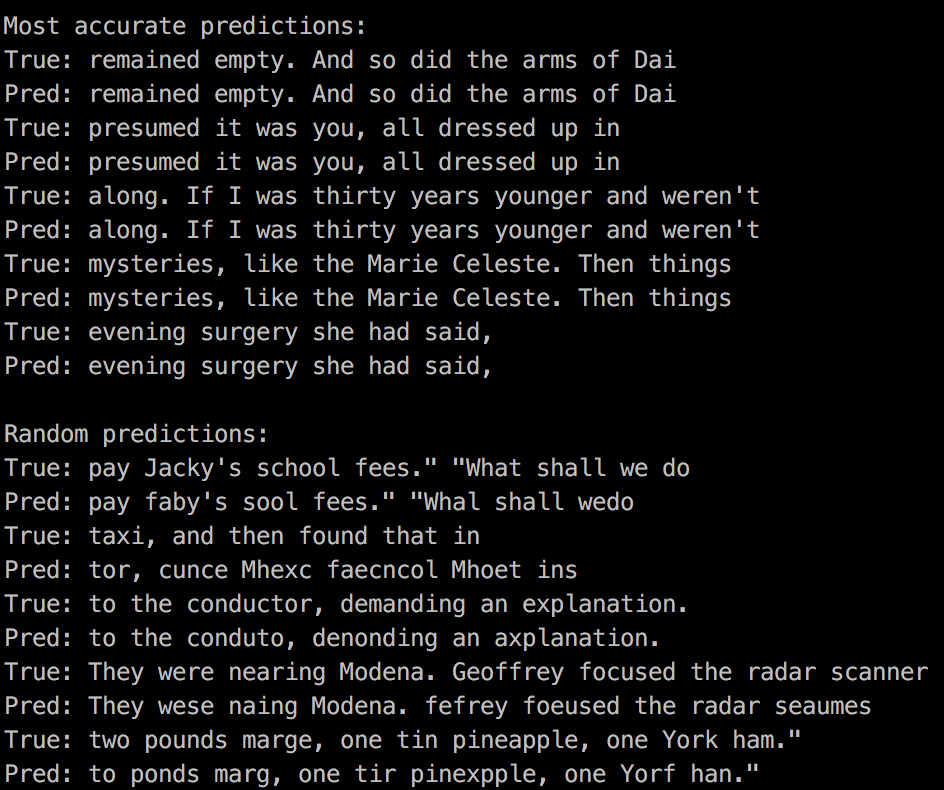
Line detection
(left to right: raw image, true label, predicted label)

Line prediction
General Learnings
Abstraction from Network to Model
The model architecture in this project aligns with the convergence of DL model design: 1. there’s a network we train and predict and it only deals with numericals; 2. On top of network, there’s a wrapper (called Model in this project) that interacts with the real world (e.g. inputs a raw image, outputs predicted classes). Thus, Model contains util functions to transform real world intputs into numericals (which are fed to Network) and transform numerical outputs from Network into real world objects.
The Model contains Data, Config, and Network, and these are exactly the deterministic ingredients for a ML model. From this we also know how to track and version a model during ML training: for input we track its data source, source code (defining the neural net architecture or a traditional ML model logic) and config (hyperparameters), for output we track its artifact path and the performance metric.
Separate classes for training dan prediction
In the project the Model class (which is for training and evaluation) is separated from a Predictor class (which is for serving as an app). This seems a common practice now, since Predictor just needs the util function of transforming a neural net’s output to be something for real world, and does not need NN-related methods like train/eval/loss etc.
However, separating them will cause duplicate the code for data management, config reading, and all the util functions for ‘real-world’ interaction. My personal preferred design is to first implement a Predictor to hold a network and util functions for ‘real world’ interaction, and then inherit from this class to create the Model class, to have additional methods on train/eval/loss, and data loading. At least this solves 2 problems in the project I observed (which I think are design flaws): 1. There’s only one ParagraphTextRecognizer which is a predictor, thus we won’t be able to have end-to-end test during training; 2. Both Model and Predictor directly takes Dataset, which during initiation will not only provide dataset metadata, but also download data files, which should be avoided for Predictor.
DL system is different from traditional ML system
DL system trades for less manually designed operations (preprocessing) with harder debugging process, while in traditional ML system the preprocessing logic composes a major chunk of work: instead of light util functions to transform data into NN-friendly numericals like what is done in DL systems, in traditional ML system the data science logic starts at preprocessing/featurization, where you design numerous small pieces of logic and hyperparameters to extract signal from raw data, before feeding them into a ML model (linear model, trees etc).
When I apply the design in this project to my daily work, I found it missed to address how to manage the featurization step: how do you compute features, and track and reload pre-compute features for different classes, based on the performance from the downstream ML model?
Layered design to manage data expectation
Debugging a DL is more challenging than traditional engineering code, and I think it is largely because DL code is more tolerant: the model can train even with bugs. With this property I think some convention will help: enforce and ensure what your data should look like at each step of your code. There are two cases I apply this tip:
Dataset, from raw to train-ready
You always need to take a raw data and process it to a training-ready form. Most of the time there are 3 stages: raw data, transformed data (after data-property-based processing e.g. normalization), and train-ready data (after data-shape-based processing e.g. one-hot-encoding, typing from np to tensor). To enable you debug you need to create an exit for each of these data. For example, in a SpecificDataset class you can have a .raw() to output raw data and a .transformed() to output transformed data, and you access the train-ready data in DataLoader. Many examples combined the latter two steps in one go (e.g. in PyTorch DataLoader) and I found it error prone. At least in DataLoader you can have two transformation sequences, one for data-property-based transformation and one for data-shape-based transformation, and you chain them together for training, but keep one exit for each sequence.
Data type, from raw to wrapped
During DL training, we wrap raw numbers generally in this route: raw number - numpy array - PT tensor. Do remember, they are equivalent to each other during – but only during – mathematical operations. Thus, it is better to keep data type consistent within a stage when doing whatever operation. Otherwise, you might forget that when reading an image numpy respects HWC shape while PT takes (N)CHW shape. Or, when you are working on NLP and wanting to reconstruct a string based on some prediction, you might forget your prediction is actually a tensor array thus your vocabulary dict won’t have any key for it (and likely you will use vocab.get(token, '') to ignore unknown predcitions which means the code will not fail). These will cost you hours to debug, which you can simply avoid by enforcing data typing at the start and the end of each stage. Once you find your code runs, you can gradually remove them if there’s performance concern.
Philosophy of Keras and PT
During this practice of modifying from Keras to PT, I can resonate why people say Keras is easy to use but rigid, while PT is flexible. For example, Keras has this .fit() API which I think that anyone touches ML will resonate, and in PT it’s always frustrating to write logic for train() and evaluate(), with the well known signature:
# in train stage
opt.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
opt.step()
# in evaluation stage
model.eval()
with torch.no_grad():
do_something()
Unless you are a DL researcher (not even DL engineer or someone using DL for scientific research), almost for sure you don’t need this. Even worse, you might forget it if you don’t actively work on it, in which one single line of code with screw your training without you noticing it because the code won’t fail.
However, with PT’s flexibility you rest assured there got to be a way of doing something, no matter how exotic or unconventional ‘something’ is. By contrast, in Keras you either find a function exactly called do_something(), or likely there’s no way to doing it. I have this feeling of (over-)specificity of design from the Keras API TimeDistributed() that is used in this project, which is essentially a window function that samples one dimension and outputs to another.
MLOps is hard and changing fast (hasn’t settled)
My last learning is that MLOps is hard and the tooling is still evolving fast (i.e. no convention). The first version of this project (Mar 2018 to 2019) was using pipenv for env management, and Dockerfile + serverless framework for serving, while now (2020) it is using conda + pip-tools for env management, and a vendor render.com for serving.
Environment management
I personally prefer stability than richer/better features. Thus for env management, I use conda (+pip for those unavailable in conda, and +mambda for local dev). There are also other management tools like poetry (mostly positive feedback but still far from being popular) and pipenv (dead for some time, active again in 2020) that seem reasonable, but who knows if they will just come and go. I was especially frustrated when I have to learn and debug pipenv simply in order to run the repo the first time, even when I already know all the DL pieces and have my way of env management. However, I admit conda’s session activation in CI is an additional pain.
The newly used pip-tools seems decent and its main usage is to read in your handcrafted dependency file and output the TRUE dependencies. However, I think: 1. Having >1 dependency files is always confusing (why are there a file for partial dependency as input and one for full dependency as output, staying side by side?). 2. You always need to figure out the true dependencies in some way if you want to share the app, so why not simply provide ONE file as the single source of truth? Given the low frequency of changing environment after you finish developing it, most likely this environment logging is just a one-time effort. 3. If you want to deploy the app in AWS Lambda (like me), you will have to do this due diligence no matter what.
Model serving
The repo used Flask library and wraps it into a Docker image and then deployed the image as a whole. While it is easy for development because we are familiar with Flask’s API, it is a bad practice to throw a whole image into AWS Lambda. However, I agree that a Dockerized ML model makes more sense and unfortunately Lambda in its current form is not very suitable for ML serving use cases: the C-bindings of ML library and the model weights can easily exceed the Lambda 250MB limit. With workaround using S3 you sacrifice latency while with workaround using EFS you are putting the Lambda behind a VPC which is likely a big problem if it’s being used as a public API.
Regarding the deployment method, originally by design the app was deployed to AWS Lambda with serverless framework and associated plugins (serverless-python-requirements, serverless-wsgi), while in the latest version it is via render.com. I suspect both methods are compromises as the authors want to give a quick taste how these ML endpoints look like. In my opinion, if you really want this app to work and stay stable, neither method is a good direction: 1. Wrapping a Lambda as a full-fledged server (with Docker+ Flask + WSGI) costs you a giant backbone that has nothing to do with ML and is purely ‘API sugar’, which is against the lightweight philosophy of using Lambda. With a Docker image you may use GCP Cloud Run or AWS Fargate, and in this direction you don’t need serverless framework at all. 2. If you are capable of building this project and wrapping it as a Docker image, you are likely able to leverage some remote compute (a.k.a. cloud), so why bother using another account on another website for your infra, where you have to learn new interfaces while have no idea about its stability?
I’m in the process of deploying it on Lambda using AWS SAM tool, will describe my experience and learnings in another post.
Comments